
مدلسازی و پیشبینی رشد سئو با تحلیل دادههای سرچ کنسول در سال 2025
مدلسازی و پیشبینی رشد سئو با تحلیل دادههای سرچ کنسول در سال 2025
مدلسازی و پیشبینی رشد سئو دیگر یک انتخاب لوکس نیست؛ در سال 2025 با تنوع نتایج جستجو، حضور هوش مصنوعی در SERPها، و حساسیت بیشتر به تجربه کاربری، تصمیمهای سئو باید دادهمحور، سناریومحور و قابل ردیابی باشد. دادههای سرچ کنسول بهعنوان دقیقترین منبع برای نمایش، کلیک، CTR و موقعیت میانگین، ستون فقرات این تصمیمسازی را شکل میدهند. در این مقاله یک چارچوب عملی و قابل اجرا برای استخراج، پاکسازی، مدلسازی و پیشبینی رشد سئو بر اساس دادههای سرچ کنسول ارائه میکنیم تا بتوانید اهداف واقعبینانه تعیین کنید، اهرمهای رشد را بشناسید و ریسکها را بهموقع کنترل کنید.
چرا مدلسازی رشد سئو در 2025 حیاتی است؟
الگوی مصرف جستجو در 2025 پویاتر از گذشته است. رفتار کاربر بین کوئریهای اطلاعاتی، مقایسهای و تراکنشی جابهجا میشود، نتایج جستجو با بلوکهای تعاملی و پاسخهای هوشمند غنیتر شدهاند، و کلیکهای بدون کلیک سهم قابلتوجهی از سفر کاربر را به خود اختصاص میدهند. در چنین شرایطی اتکا به گزارشهای توصیفی گذشته کافی نیست؛ شما به پیشبینی نیاز دارید تا منابع تولید محتوا، بهبود فنی و لینکبیلدینگ را بهینه تخصیص دهید، اهداف ماهانه را مستند کنید و اثر اقدامات را جدا از نویز بازار بسنجید.
تفاوت پیشبینی و هدفگذاری در سئو
هدفگذاری سئو تعیین نقطه مطلوب است، اما پیشبینی برآورد محتملترین مسیر رسیدن به آن نقطه براساس روندهای تاریخی و متغیرهای اثرگذار است. پیشبینی باید مستقل از آرزوها باشد و با عدمقطعیت همراه شود؛ یعنی برای هر سناریو یک بازه اطمینان داشته باشیم. سپس چرخه برنامهریزی با فاصله اهداف و پیشبینی، شکافها را به اهرمهای عملیاتی (بهبود CTR، ارتقای موقعیت، افزایش عمق محتوایی) ترجمه میکند.
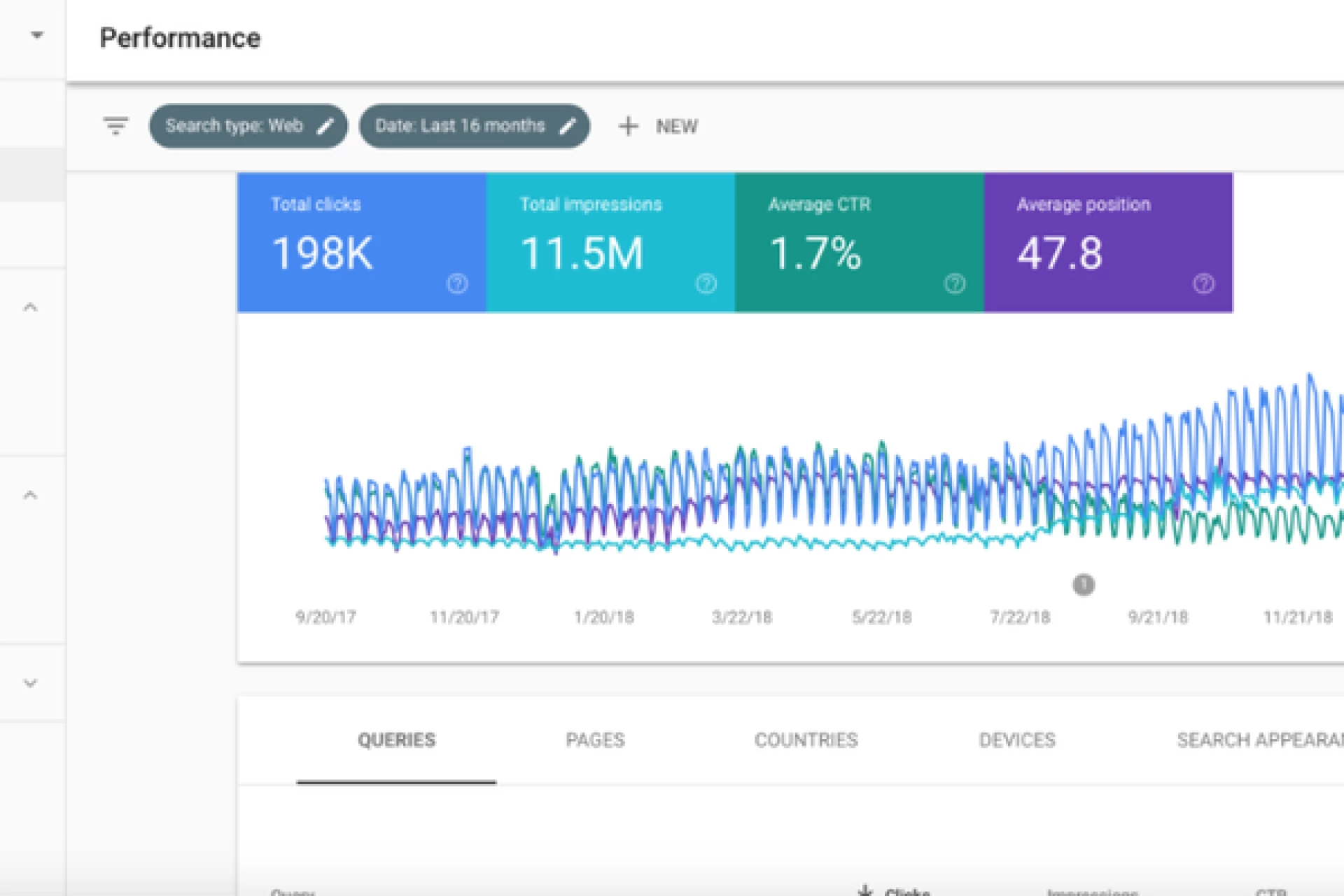
متریکهای کلیدی سرچ کنسول برای مدلسازی
در هسته مدلسازی، چهار متریک اصلی سرچ کنسول قرار دارد: تعداد نمایشها (Impressions) بهعنوان نماینده تقاضای بازار و میزان حضور شما در SERP؛ تعداد کلیکها (Clicks) بهعنوان خروجی واقعی جذب ترافیک؛ نرخ کلیک (CTR) که کیفیت حضور شما در نتایج را منعکس میکند؛ و موقعیت میانگین (Average Position) بهعنوان شاخص قدرت رتبه. ترکیب این چهار شاخص با ابعاد Query، Page، Device، Country و Search Appearance امکان شکستن دادهها به خوشههای معنادار را فراهم میکند. تفکیک برند/غیربرند، دستگاه موبایل/دسکتاپ و کشور هدف برای هر مدل ضروری است تا رفتارهای متفاوت با هم مخلوط نشوند.
آمادهسازی دادهها از سرچ کنسول
کیفیت مدل به کیفیت داده بستگی دارد. بهجای تکیه بر خروجیهای دستی، از ابتدا یک خط لوله داده پایدار بسازید تا بازیابی، پاکسازی و غنیسازی اطلاعات بهصورت تکرارشونده انجام شود.
روشهای استخراج: رابط کاربری، API و Bulk Export
سه مسیر برای استخراج داده وجود دارد. رابط کاربری برای تحلیلهای سریع مناسب است اما برای مدلسازی محدود است. API سرچ آنالیتیکس امکان دریافت دادههای سری زمانی با ترکیبهای دلخواه ابعاد را فراهم میکند و حداکثر ردیف هر درخواست محدود است؛ بنابراین لازم است صفحهبندی و زمانبندی درخواستها رعایت شود. در نهایت، Bulk Export به BigQuery راهحل استاندارد برای ذخیرهسازی بلندمدت دادههای روزانه است؛ این روش محدودیت 16 ماهه رابط کاربری را دور میزند و امکان پیوند دادههای سرچ کنسول با سایر منابع سازمانی را مهیا میکند.
ساختار داده و دانهبندی
قبل از هر چیز تصمیم بگیرید مدل شما در چه دانهبندیای خروجی میدهد: سطح کل سایت، خوشه موضوعی، الگوی صفحه، یا URL. دانهبندی هرچه ریزتر باشد نویز بیشتر است و مدل پیچیدهتر میشود. برای پیشبینی رشد کل سایت از دادههای روزانه در افقهای هفتگی/ماهیانه استفاده کنید تا نوسانات کوتاهمدت خنثی شوند. برای خوشهها و صفحات مهم، رولآپ روزانه به هفتگی با میانگین متحرک 7 و 14 روزه، سیگنالها را باثبات میکند.
پاکسازی، نرمالسازی و مدیریت دادههای ناشناس
جدا از حذف سطرهای تکراری و همگنسازی نامکها، باید کوئریهای ناشناس یا کمحجم را مدیریت کنید. سرچ کنسول برای حفظ حریم خصوصی بخشی از کوئریهای بسیار کمجستجو را تجمیع یا ناشناس میکند. سهم این بخش را در سطح کلان اندازه بگیرید تا برآوردی از تقاضای واقعی داشته باشید، اما از وارد کردن آن به مدلهای جزئی خودداری کنید. همچنین تغییرات ساختاری سایت (ریدایرکتها، ادغام صفحات، تغییر الگو) را با جدول نگاشت ثبت کنید تا شکست سری زمانی رخ ندهد.
تقسیمبندی برند/غیربرند و خوشهبندی کوئریها
پیشبینی باید با تفکیک برند و غیربرند انجام شود؛ رفتار CTR، موقعیت و کشش رشد این دو گروه متفاوت است. از فهرست کلیدواژههای برند، نام محصول، دامنه و اشتباهات املایی برای جداسازی استفاده کنید. سپس با ترکیب قواعد متنی، شباهتهای معنایی و قصد جستجو، کوئریها را به خوشههای موضوعی تبدیل کنید. خروجی را در سطح خوشه به صفحات مقصد متصل کنید تا بتوانید «نقشه رشد» از تقاضا تا محتوا و رتبه را ترسیم کنید.
ساخت شاخصهای پیشرو و KPIهای پایش
پیشبینی تنها با کلیک و نمایش ممکن نیست. نیاز دارید شاخصهایی بسازید که زودتر از کلیک تغییر میکنند و هشدار میدهند. این شاخصها موتور سناریوسازی و بودجهبندی اقدامات شما خواهند بود.
تعریف اهداف و معیارهای موفقیت
اهداف باید مشخص، قابلسنجش، دستیافتنی و زماندار باشند. مثال: افزایش 25 درصدی کلیکهای غیر برند در بازار ایران تا پایان فصل با حفظ CTR بالاتر از 4 درصد و بهبود موقعیت میانگین خوشه «راهنماهای آموزشی» به کمتر از 9.5. این هدف به سه اهرم عملیاتی ترجمه میشود: افزایش نمایش با تولید محتوا، بهبود رتبه با بهینهسازی داخلی و لینکسازی، و بهبود CTR با بهینهسازی عناوین و نتایج غنی.
شاخصهای پیشرو که باید دنبال کنید
توزیع موقعیت بهتفکیک بازهها (1–3، 4–10، 11–20) برای خوشههای مهم سیگنال زودهنگام رشد است؛ انتقال کوئریها به بازههای بهتر، اثر کلیک را در هفتههای بعدی رقم میزند. نرخ عبور Core Web Vitals بهصورت درصد صفحات عبوری، شاخصی است که بر رتبه و CTR اثر غیرمستقیم دارد. سهم نمایشهای بالای Fold برای دستگاه موبایل، نسبت URLهای ایندکسشده به ارسالشده، و نسبت صفحات دارای اسکیما به کل صفحات گروه نیز در نقش محرکهای اولیه عمل میکنند.
قیف سئو: از نمایش تا کلیک و جلسه
هرچند سرچ کنسول جلسه را گزارش نمیکند، اما میتوانید قیفی از نمایش تا کلیک و سپس تا نشست در آنالیتیکس ترسیم کنید. برای مدلسازی رشد سئو، رابطه سادهای راهنماست: کلیک = نمایش × CTR. سپس CTR تابعی از موقعیت، ظاهر جستجو و جذابیت عنوان/متا است. با داشتن منحنی CTR برحسب موقعیت برای هر خوشه، میتوانید اثر هر واحد بهبود رتبه را بر کلیک تخمین بزنید و برنامه بهینهسازی را اولویتبندی کنید.
مدلهای زمانسری برای پیشبینی
وقتی سری زمانی کلیکها و نمایشها را در دست دارید، قدم بعدی انتخاب مدل مناسب است. انتخاب مدل باید به افق پیشبینی، فصلی بودن تقاضا و وجود شوکها بستگی داشته باشد.
ARIMA و SARIMA برای روندهای پایدار
ARIMA برای سریهای ایستای تبدیلشده و SARIMA برای فصلهای منظم (مانند الگوهای هفتگی و ماهانه) استفاده میشود. برای سایتهایی که رشد ارگانیک نسبتا باثبات دارند و شوکهای بیرونی محدود است، SARIMA با پارامترهای هفتگی و ماهانه میتواند کلیکهای تجمیعی هفتگی را با دقت مناسب پیشبینی کند. قبل از برازش، از تفاضلگیری برای ایستا کردن سری و از آزمونهای ایستایی استفاده کنید، سپس باقیماندهها را بررسی کنید تا خودهمبستگی ناخواسته باقی نمانده باشد.
مدلهای افزودنی با فصلهای چندگانه
وقتی فصلی بودن پیچیده است یا تعطیلات و رویدادها اثر قابلتوجه دارند، مدلهای افزودنی با روند غیرخطی و فصلهای چندسطحی مفید هستند. این مدلها امکان اضافه کردن تعطیلات ملی، کمپینهای برند، و آغاز/پایان فصلهای خرید را بهصورت متغیرهای کمکی میدهند. نتیجه، پیشبینیهایی با باند اطمینان است که برای سناریوسازی رشد بسیار کارکردیاند.
TBATS و مدیریت چندفصلی پیچیده
برای وبسایتهایی با چند فصلی همزمان، مثل الگوهای روز هفته، آخر ماه و فصل سال، مدل TBATS بهخاطر استفاده از تبدیل باکس-کاکس، روند محلی و فصلهای با دورههای غیر صحیح گزینه مناسبی است. در تجارتهایی که رفتار جستجو در ابتدای هر ترم، هر جمعه یا نزدیک مناسبتها جهش دارد، TBATS اغلب از مدلهای کلاسیک عملکرد بهتری دارد.
متغیرهای برونزا: محتوا، لینک و نوسان SERP
زمانی که میخواهید اثر اقدامات سئو را در پیشبینی لحاظ کنید، به مدلهایی نیاز دارید که Exogenous Regressor بپذیرند. تعداد URLهای جدید ایندکسشده، تعداد بهروزرسانیهای محتوایی، نرخ عبور CWV، سرعت خزیدن، و شاخص نوسان SERP از ابزارهای ردیاب بازار میتوانند بهعنوان متغیرهای برونزا وارد شوند. این کار اجازه میدهد سناریوهای «اگر-آنگاه» بسازید: اگر در ماه آینده 30 صفحه جدید در خوشه X منتشر شود و نرخ عبور CWV به 85 درصد برسد، انتظار چه رشد کلیکی خواهیم داشت؟
مدلهای یادگیری ماشین مبتنی بر رگرسیون
وقتی روابط بین متریکها غیرخطی و متقاطع هستند، رگرسورهای مبتنی بر درخت مانند XGBoost و LightGBM در پیشبینی کلیکها و CTR بهویژه در سطح خوشه و URL قدرتمند ظاهر میشوند.
چرا رگرسورهای درختی؟
این مدلها تعاملات پیچیده بین موقعیت، نوع دستگاه، نوع صفحه، طول عنوان، وجود ریچریزلت، و فصل را بهخوبی میآموزند و نسبت به مقیاسبندی ویژگیها حساس نیستند. همچنین با ایجاد اهمیت ویژگی، به شما میگویند کدام اهرمها مهمتر بودهاند تا برنامه بهینهسازی را هدفمندتر کنید.

طراحی ویژگیها برای پیشبینی دقیق
ویژگیهای تاخیری مانند میانگین متحرک 7/14/28 روزه برای نمایش و CTR، تغییرات درصدی هفتگی، شیب روند سههفتهای، و نسبت نمایشهای رتبه 1–3 به کل نمایشها سیگنالهای قدرتمندی هستند. شاخصهای محتوایی مثل تعداد کلمات، عمق عنوان، وجود کلمات اقدام، و تازگی محتوا نیز بر CTR اثر میگذارند. از سمت فنی، امتیاز CWV، زمان بارگذاری اولین محتوا، و نسبت CLS میتواند بهعنوان ورودی استفاده شود. در سطح خوشه، شمار لینکهای داخلی تازه افزودهشده، و نسبت URLهای دارای اسکیما به کل، اثر خود را نشان میدهد.
اعتبارسنجی زمانی و Backtesting
در دادههای زمانی، اعتبارسنجی معمول با تقسیم تصادفی معنایی ندارد. از اعتبارسنجی پیشرونده استفاده کنید: یک بازه آموزش، سپس پیشبینی بازه بعدی و تکرار. معیارهای خطا مانند MAPE، sMAPE و P90 Error را گزارش کنید تا بدترینحالت را بشناسید. در کنار مدل اصلی، یک مدل ساده ناوابسته به توضیحات (مثلا میانگین 4 هفته اخیر) را بهعنوان Baseline نگه دارید؛ اگر مدل پیچیده بهتر از خط مبنا نباشد، باید بازطراحی شود.
سناریوسازی رشد و بودجهبندی سئو
پیشبینی بدون سناریو ناقص است. با ترکیب مدلها و اهرمهای اجرایی، سه سناریو بسازید: محتاطانه، خط پایه و خوشبینانه. سپس منابع و زمانبندی را متناسب با احتمال و بازگشت هر سناریو تخصیص دهید.
تعریف سناریوهای عملیاتی
سناریوی محتاطانه فرض میکند رشد تقاضا ثابت بماند و تنها بخشی از برنامه محتوایی اجرا شود. سناریوی خط پایه بر مبنای اجرای برنامه و عدم وقوع شوکهای منفی است. سناریوی خوشبینانه علاوهبر اجرای کامل برنامه، بهبود معنادار CTR از طریق تست عناوین و کسب ریچریزلت را فرض میکند. خروجی هر سناریو باید شامل کلیک، CTR، و توزیع موقعیت باشد.
اهرمهای رشد و تبدیل آنها به اعداد
برای تبدیل تاکتیکها به خروجی، از روابط ساده استفاده کنید. اگر بهبود عنوان در خوشه «راهنما» معمولا CTR را 0.6 تا 1.2 واحد درصد افزایش میدهد، و نمایش هفتگی آن خوشه 500 هزار است، میتوان انتظار 3000 تا 6000 کلیک اضافی داشت. اگر لینکسازی داخلی 10 درصد از کوئریهای رتبه 4–10 را به 1–3 منتقل کند و منحنی CTR شما نشان دهد اختلاف CTR میان این بازهها 8 واحد درصد است، میتوانید اثر ترافیکی آن حرکت را محاسبه و اولویتبندی کنید.
تحلیل عمیق در سطح صفحه، الگو و خوشه
مدیریت سئو در مقیاس نیازمند نگاه لایهای است. هر لایه زبان خاص خود را دارد و اهرمهای متفاوتی در اختیار شما میگذارد.
تحلیل الگو (Template-Level)
الگوها مانند صفحات لیست، مقالات، محصول یا دستهبندی رفتار CTR و ایندکس متفاوت دارند. با تجمیع داده به تفکیک الگو، میتوانید بفهمید کدام الگو نیاز به اصلاح ساختار H1، BreadCrumb، اسکیما یا بهبود سرعت دارد. این دید به اولویتبندی فنی و محتوایی کمک میکند و اثر بهبود الگو را بر دهها یا صدها URL تسری میدهد.
تحلیل خوشه و قصد جستجو
هر خوشه باید با هدف کاربر همراستا باشد. در خوشههای اطلاعاتی، بهبود CTR بیشتر از جایگاه با افزودن خلاصه پاسخ، تیترهای روشن و بخش سوالات متداول بهدست میآید. در خوشههای تراکنشی، نوسان قیمت، موجودی و ریچریزلتها بر CTR حاکماند. توزیع موقعیت در هر خوشه را جداگانه تحلیل کنید؛ گاهی میانگین موقعیت ثابت است اما درصد نمایش در رتبههای 1–3 رو به رشد است که سیگنال مثبت تلقی میشود.
تفکیک دستگاه و جغرافیا
الگوی CTR و موقعیت برای موبایل و دسکتاپ یکسان نیست. اسکرول پیوسته در موبایل منحنی CTR را کشیدهتر کرده و فرصت برای نتایج رتبههای 5 تا 10 بیشتر است. همچنین تفاوتهای زبانی و محلیسازی بر CTR اثر میگذارد. پیشبینی را برای بازارهای کلیدی و دستگاهها جداگانه انجام دهید و سپس تجمیع کنید تا تصویر کل سایت حاصل شود.
تشخیص ناهنجاری و پایش ریسک
هیچ مدلی بدون سیستم پایش مستمر و تشخیص ناهنجاری پایدار نیست. شما باید بدانید چه زمانی روند از محدوده انتظار خارج شده و علت احتمالی چیست.
آستانههای پویا و باند اطمینان
برای هر خوشه و سطح کل سایت، باندهای اطمینان بر اساس انحراف معیار خطای پیشبینی بسازید. وقتی کلیک یا نمایش از این باند خارج شد، هشدار ایجاد کنید. باند پویا بهتر از آستانه ثابت عمل میکند چون با فصلها و نوسانات سازگار است.
تفکیک ریشه مشکل: تقاضا، رتبه یا CTR
سه علت اصلی افت ترافیک ارگانیک عبارتند از: افت تقاضا (کاهش نمایش بدون تغییر قابلتوجه رتبه و CTR)، افت رتبه (بدتر شدن موقعیت و در پی آن کاهش CTR و کلیک)، و تغییرات SERP که CTR را کاهش میدهد با وجود ثبات موقعیت. با نمودارهای همزمان نمایش، موقعیت و CTR میتوانید فوراً تشخیص دهید کدام عامل غالب است و راهحل مناسب را انتخاب کنید.
داشبورد و هشداردهی
داشبوردهای خودکار با اتصال سرچ کنسول، انبار داده و ابزار گزارشسازی، دید روزانه تا ماهانه را فراهم میکنند. هشدارهای ایمیلی یا پیامرسان برای جهشهای غیرعادی در نمایش، CTR یا موقعیت، زمان واکنش را به حداقل میرسانند. تعریف سطح آستانه اختصاصی برای صفحات پولساز یا خوشههای استراتژیک ضروری است.
آزمایشهای سئو و نسبت دادن اثر
مدلسازی رشد وقتی ارزشمندتر میشود که بتوان اثر اقدامات را بهصورت علّی بسنجید. آزمایش کنترلشده و طراحی آماری، مکمل پیشبینی است.
تستهای A/B، Split و Holdout
در سئو، A/B واقعی دشوار است اما میتوان با تقسیم URLها به گروه آزمایش و کنترل و اعمال تغییر در گروه آزمایش، اثر را سنجید. باید اطمینان حاصل کرد که خوشه و الگو در دو گروه مشابهاند. همچنین میتوان آزمایشهای برش زمانی اجرا کرد: تغییر در بازه مشخص و مقایسه با دورههای مشابه تاریخی و گروههای کنترل همزمان.
تحلیل علّی با Difference-in-Differences و Impact
روش اختلاف در اختلافها با فرض روندهای موازی، اثر خالص تغییرات را بر کلیک و CTR نشان میدهد. مدلهای اثر علّی نیز برای سنجش مداخلات در حضور روندهای زمانسری مناسباند. خروجی این تحلیلها برای بهروزرسانی پیشفرضها در سناریوسازی آینده حیاتی است.
الزامات 2025: حریم خصوصی و تغییرات SERP
دو جریان بزرگ در 2025 بر مدلسازی اثر میگذارند: تغییرات حریم خصوصی و تکامل نتایج جستجو. باید اثر هر دو را در طراحی سیستمهای پیشبینی لحاظ کنید.
حذف تدریجی کوکیهای شخص ثالث و اثر بر اندازهگیری
هرچند سرچ کنسول مستقل از کوکیهای شخص ثالث است، اما برای نسبت دادن ارزش کسبوکار به ترافیک ارگانیک و اتصال به آنالیتیکس باید از روشهای مقاوم به حریم خصوصی استفاده کنید. یکپارچهسازی سمت سرور و استفاده از شناسههای نخستطرف، اتصال دادههای سرچ کنسول با دادههای تبدیل در سطح تجمیعی، و رعایت حداقلسازی داده حساس، باعث میشود مدلها پایدار بمانند.
پاسخهای هوشمند و کلیکهای بدون کلیک
حضور پررنگتر پاسخهای هوشمند در SERP میتواند نسبت کلیک به نمایش را برای برخی کوئریهای اطلاعاتی کاهش دهد. برای پیشبینی واقعبینانه، منحنی CTR را بهصورت دورهای بازآموزی کنید و اثر انواع ظاهر جستجو را در مدل جداگانه لحاظ کنید. اگر سرچ کنسول دستهبندیهای جدیدی به Search Appearance اضافه کند، آنها را جداگانه رصد و مدل کنید تا تصویر شفافتری داشته باشید.
اسکرول پیوسته و شکل جدید منحنی CTR
اسکرول پیوسته در نتایج باعث شده سهم کلیک ردیفهای 5 تا 10 نسبت به گذشته در موبایل کاهش یا افزایش نسبی داشته باشد که به نوع کوئری وابسته است. بنابراین به جای تکیه بر جداول عمومی CTR، منحنی CTR اختصاصی خود را در هر خوشه و دستگاه استخراج کنید و در محاسبات سناریویی بهکار ببرید.
پیادهسازی عملی: از صفر تا پیشبینی
برای تبدیل مفاهیم به خروجی عملی، مسیر زیر را پیشنهاد میکنیم: طراحی خط لوله داده، مهندسی ویژگی، انتخاب مدل، صحهگذاری، و یکپارچهسازی با داشبورد و سناریوسازی.
ایجاد خط لوله داده
ابتدا ویژگی Bulk Export به انبار داده را فعال کنید تا از امروز به بعد دادههای روزانه ذخیره شوند. در کنار آن، برای ابعاد خاص، دادههای تاریخی 16 ماهه را با API دریافت و در همان انبار داده ذخیره کنید. جداول مرجع برای نگاشت URLهای ادغامشده، فهرست برندترمها، خوشههای موضوعی و الگوها بسازید. کیفیت داده را با آزمونهای واحدی مانند عدم وجود URLهای تکراری، کامل بودن فیلدها و همخوانی مجموع نمایشها بین سطوح بررسی کنید.
مدلسازی و گزارشدهی
برای سطح کل سایت، مدل زمانسری با فصلهای هفتگی/ماهیانه کفایت میکند. برای خوشهها و URLهای استراتژیک، رگرسورهای غیرخطی را اضافه کنید. خروجی هر مدل باید شامل نقطه پیشبینی، باندهای اطمینان و تجزیه به عوامل باشد: سهم تغییرات تقاضا (Impressions)، سهم بهبود رتبه (Position)، و سهم تغییر CTR. در داشبورد، امکان فیلتر برحسب کشور، دستگاه، خوشه، الگو و برند/غیربرند را فراهم کنید.

چرخه بازنگری ماهانه
هر ماه مدلها را با دادههای جدید بازآموزی کنید، خطاها را بسنجید، و مفروضات سناریو را بهروزرسانی کنید. اگر باند خطا گسترش یافت، بررسی کنید آیا شوک ساختاری رخ داده یا کیفیت داده کاهش یافته است. نتایج آزمایشهای ماه قبل را در مدل لحاظ کنید تا پیشبینیها نهتنها دقیقتر، بلکه عملیتر شوند.
اشتباهات رایج و بهترینعملها
در مسیر مدلسازی سئو دامهایی وجود دارد که با آگاهی از آنها میتوان از هدررفت منابع جلوگیری کرد و خروجی قابل اتکا تحویل داد.
دامهای متداول
اختلاط دادههای برند و غیربرند باعث بزرگنمایی رشد میشود و تصویر غلطی از عملکرد میسازد. اتکا به میانگین موقعیت بدون تحلیل توزیع رتبه، میتواند به تصمیمهای نادرست منجر شود. استفاده از دادههای سطح URL با حجم بسیار کم، مدل را پر از نویز میکند. نادیده گرفتن تغییرات SERP و فصلها، سناریوها را غیرواقعی میکند. همچنین فراموش کردن اثر تأخیر اقدامات سئو باعث میشود زمانبندی پیشبینیها نادرست باشد.
بهترینعملها
همیشه یک خط مبنا برای مقایسه داشته باشید. مدل را با دادههای بیرونی غنی کنید اما فقط تا جایی که کیفیت داده اجازه میدهد. منحنیهای CTR اختصاصی بسازید و آنها را بهصورت فصلی بهروزرسانی کنید. تفکیک دستگاه و کشور را جدی بگیرید. بهجای تمرکز بر یک متریک، سبدی از شاخصهای پیشرو و پسرو داشته باشید. و در نهایت، نتایج مدل را به برنامه اقدام قابلاندازهگیری ترجمه کنید تا حلقه بسته بهبود شکل بگیرد.
نتیجهگیری
مدلسازی و پیشبینی رشد سئو در 2025 با تکیه بر دادههای سرچ کنسول، به شما امکان میدهد از تحلیلهای گذشتهنگر فاصله بگیرید و به برنامهریزی آیندهنگر برسید. با ساخت خط لوله داده پایدار، تفکیک هوشمندانه خوشهها و برند/غیربرند، انتخاب مدل متناسب با ماهیت سری زمانی، و سناریوسازی مبتنی بر اهرمهای واقعی، میتوانید رشد ارگانیک را قابل پیشبینی، قابلمدیریت و قابلدفاع کنید.
در نهایت، پیشبینی یک فرآیند زنده است. با هر بهروزرسانی الگوریتم، با هر تغییر در رفتار کاربر و با هر اقدام محتوایی یا فنی، مدل باید یاد بگیرد و خود را تطبیق دهد. این چابکی، مزیت رقابتی شما در بازار جستجو خواهد بود.
بهترین افق زمانی برای پیشبینی رشد سئو چقدر است؟
برای تصمیمسازی عملی، افق 8 تا 12 هفته برای اجرای تاکتیکها و سنجش اثر مناسب است. در سطح استراتژی، سناریوهای فصلی و سالانه نیز تهیه کنید، اما آنها را ماهانه بازنگری کنید.
آیا میتوان فقط با دادههای رابط کاربری سرچ کنسول پیشبینی کرد؟
برای تحلیلهای سریع بله، اما برای مدلسازی پایدار توصیه میشود از API یا Bulk Export استفاده کنید تا محدودیتهای دانهبندی و بازه زمانی، کیفیت پیشبینی را مختل نکند.
چگونه اثر اقدامات سئو را از تغییرات تقاضای بازار جدا کنیم؟
با تفکیک سه جزء نمایش، موقعیت و CTR و استفاده از گروههای کنترل یا روشهای علّی، میتوان سهم اقدامات از تغییرات ترافیک را برآورد کرد و به سناریوها منتقل نمود.
برای خوشههای کمداده چه مدلی مناسب است؟
برای خوشههای کوچک، تجمیع هفتگی، استفاده از میانگینهای متحرک و مدلهای سادهتر با ویژگیهای محدود، عملکرد بهتری دارند. همچنین میتوانید خوشههای مشابه را موقتا ادغام کنید.
آیا تغییرات الگوریتمی پیشبینیها را بیاعتبار میکند؟
شوکهای الگوریتمی میتوانند خطای کوتاهمدت ایجاد کنند. با سیستم تشخیص ناهنجاری، بازآموزی سریع مدل و بهروزرسانی سناریوها، میتوان اثر آنها را کنترل و پیشبینیها را پایدار نگه داشت.
پست های مشابه

03
دی
28
آذر

18
آذر





